- 10, Apr 2020
- #1
WinSoft Optical Character Recognition (OCR)
more info OCR
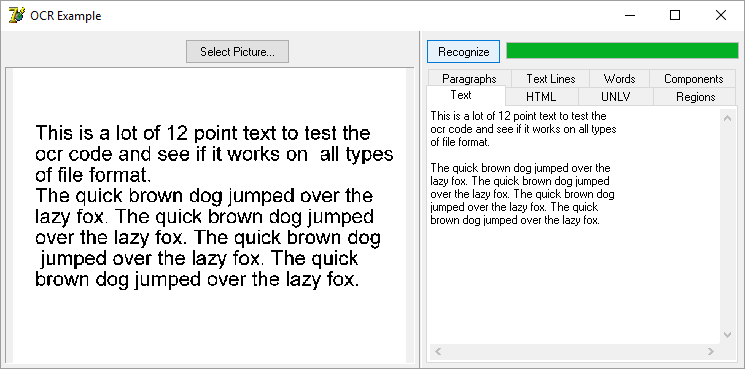
Optical Character Recognition is an OCR component for retrieving text from an image, for example, from a scanned paper document.
Tesseract is the most accurate open source OCR engine, and combining it with the Leptonica image processing library makes it possible to read a wide range of image formats and convert them to more than 60 languages.
This vehicle was one of the best 3 top engines in the 1995 UNLV Accuracy Test. Between 1995 and 2006, a bit of work was done on it, but has since been improved by Google and released under the Apache 2.0 license.
The Leptonica Library is useful for many operations on visual documents and natural images.
The features of the Leptonica library include skylight, rotation, translate images to the desired pixel depth, binary morphology, and white black, image conversion with a change in pixel depth.
Use OCR component to retrieve text from image, for example from scanned paper document.
FAQ
How can I solve "Cannot initialize Tesseract library" error?
Set Ocr.DataPath property to the folder containing Tessseract language data files.
How can I increase OCR speed?
Use Tesseract language data from tessdata_fast
repository.
How can I increase OCR accuracy?
Use Tesseract language data from tessdata_best
repository.
How can I improve OCR output?
GitHub: Improving the quality of the output
Optical Character Recognition is an OCR component for retrieving text from an image, for example, from a scanned paper document.
Tesseract is the most accurate open source OCR engine, and combining it with the Leptonica image processing library makes it possible to read a wide range of image formats and convert them to more than 60 languages.
This vehicle was one of the best 3 top engines in the 1995 UNLV Accuracy Test. Between 1995 and 2006, a bit of work was done on it, but has since been improved by Google and released under the Apache 2.0 license.
The Leptonica Library is useful for many operations on visual documents and natural images.
The features of the Leptonica library include skylight, rotation, translate images to the desired pixel depth, binary morphology, and white black, image conversion with a change in pixel depth.
Use OCR component to retrieve text from image, for example from scanned paper document.
- uses Tesseract OCR engine and Leptonica image processing library
- available for Delphi/C++ Builder 5 - 10.2 and Lazarus 1.8.4
- source code included in registered version
- royalty free distribution in applications
FAQ
How can I solve "Cannot initialize Tesseract library" error?
Set Ocr.DataPath property to the folder containing Tessseract language data files.
How can I increase OCR speed?
Use Tesseract language data from tessdata_fast
repository.
How can I increase OCR accuracy?
Use Tesseract language data from tessdata_best
repository.
How can I improve OCR output?
GitHub: Improving the quality of the output

