Итак форум на четверке намбер 2.
В этом посте я опишу особенности, с которыми столкнулся при установке еще одного форума на рандомно выбранном хостинге. И в частности
на хостинге с php 5.4
Поначалу все происходило как обычно.
Взял дистрибутив 4.2.0, залил его на хостинг, и...
Нифига.
Ошибка установки.
Strict Standards: Non-static method vB_Shutdown::instance() should not be called statically, assuming $this from incompatible context in ну и тут дальше путь и прочее
Посмотрел, версия php на хостинге 5.4. Понятненько.
Идем в папку инсталл, открываем файл init.php, находим строку
@ini_set('display_errors', true)
Заккоментируем ее, выполняем рекомендации по ссылке:
https://lumtu.com/vbulletin-4-x-x/6536-forum-na-vbulletin-4-2-a.html#post62347
, и запускаем инсталляцию.
Форум установился как часы.
Даже не подозревая сколь долго придется колупать этот форум, я пошел в админку устанавливать русификатор.
Выбрал русификатор в utf-8, загрузил язык, открыл главную форума, и....
А весь форум оказался вот таким: ?????
Вместо кириллицы все оказалось в знаках вопроса.
Конечно, первым делом у меня была мысль взять на месяц другой хостинг, где я уже ставил четверку vBulletin, там все реализовать, а затем переехать.
Но ведь это не дело.
Но ведь нужно разобраться со всеми тонкостями установки форума, с кодировками базы данных, чтобы в дальнейшем, если придется тратить на установку и настройку минимальное количество времени.
Так я и моя тень на этом и порешили.
Так как же правильно установить четверку на обычном, стандартном шаред хостинге, чтобы не было проблем в дальнейшем?
Рассказываю пошагово.
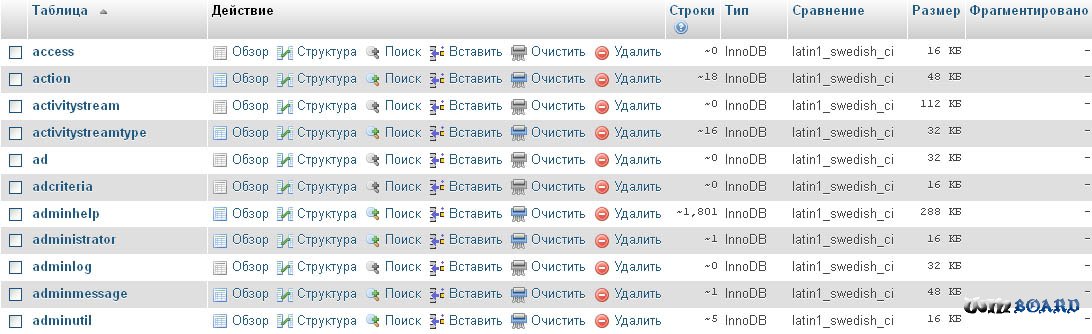
Перво наперво идем в ПМА, кликаем на вашу базу данных, и смотрим сопоставление таблиц. У меня, как и на большинстве стандартных хостингов оно оказалось в кодировке latin1
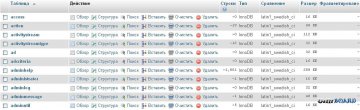
Соответственно, если кликнуть на таблицу, то и индексы со столбцами также будут в кодировке latin1
Ремонт нашей базы данных нужно начинать сразу после установки форума, ДО установки русификатора, на абсолютно чистый форум.
И что делать дальше?
Если вручную делать сопоставление для каждой таблицы в кодировке utf8, то и полдня можно просидеть.
В четверке 246 таблиц, в каждой таблице черт знает сколько полей, и так далее.
Естественно, меня такое не устраивало, и как-то хотелось автоматизировать процесс.
И решение было найдено.
Дело в том, что php 5 и выше позволяет делать запрос:
ALTER TABLE имя_вашей_бд CONVERT TO CHARACTER SET utf8 [COLLATE collation_name]
Но для каждого поля подобный запрос делать не выход, поэтому делаем вызов запросов для всех таблиц вашей БД
SELECT CONCAT('ALTER TABLE `', t.`TABLE_SCHEMA`, '`.`', t.`TABLE_NAME`, '` CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;') as sqlcode
FROM `information_schema`.`TABLES` t
WHERE 1
AND t.`TABLE_SCHEMA` = 'имя_вашей_бд'
ORDER BY 1
Где имя_вашей_бд - имя вашей базы данных.
После данного запроса мы получим список следующего вида:
ALTER TABLE `имя_вашей_бд`.`access` CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;
ALTER TABLE `имя_вашей_бд`.`announcementread` CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;
ALTER TABLE `имя_вашей_бд`.`noticedismissed` CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;
Где имя_вашей_бд - имя вашей базы данных, и количеством в 246 штук.
Теперь копируем это все, и выполняем сиквел запрос.
Я бы рекомендовал эти 246 запросов разбить на части, по 50-100 штук, иначе хостинг может уйти в даун, если конечно это не сервер и вы работаете на шареде.
Казалось бы все? Но нет.
На запросе
ALTER TABLE `имя_вашей_бд`.`phrase` CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;
выскакивает ошибка, и таблица не переводится в нужную нам кодировку.
Ошибка появляется следующего вида:
ERROR 1062 (23000) at line 49: Duplicate entry 'common.langDirLtr--1-ckeditor' for key 2
Поэтому
перед тем, как дробить наши 246 запросов, и менять сопоставление кодировки, необходимо привести в порядок таблицу phrase.
Это фразы vBulletin.
Не знаю чего там намудрили, но во фразах есть четыре поля:
common.langDirLTR
common.langDirLtr
и
common.langDirRTL
common.langDirRtl
Поэтому тупая БД видит дубликаты, и ничего не меняет.
Я просто удалил два поля common.langDirLTR и common.langDirRTL и оставил дубли в нижнем регистре.
Все.
Мы привели в порядок таблицу, сделали 246 запросов к БД, и все вобловские таблицы где есть
в индексах и столбцах сопоставление кодировок пришли в нужный вид.
Наверное можно было бы оставить и так, и больше не возникло бы проблем с кодировками, но мне хотелось сделать как положено, ибо часть таблиц, где не пишутся данные в кодировке так и остались в latin1. Точную цифру я не уточнял, но это порядка 50-70 штук.
Дампером я сделал бэкап БД и сохранил его на компьютере.
Далее дамп базы данных открываем Notepad ++ или AkelPad и делаем замену на оставшиеся таблицы в сопоставлении latin1. Для этого открываем функцию поиска и замены, искомая фраза CHARSET=latin1 фраза под замену CHARSET=utf8. Сохраняем изменения и импортируем дамп.
Теперь, если вы зайдете в ПМА, то увидите, что сопоставление кодировки стало везде в utf8
Теперь с чистой совестью можно ставить русификатор, и ваш форум больше не будет выглядеть знаками вопроса ??? а будет иметь вполне себе читабельный вид.
vBulletin 4.2.0 и php 5.4 мы еще подружили не совсем.
На этой версии пхп в 4.2.0 не генерируются миниатюры.
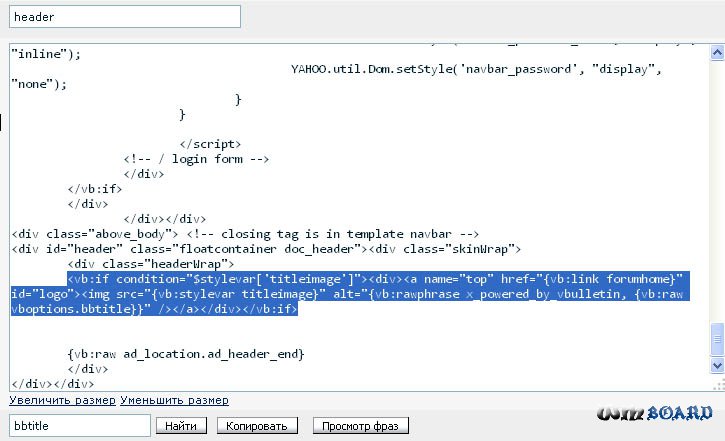
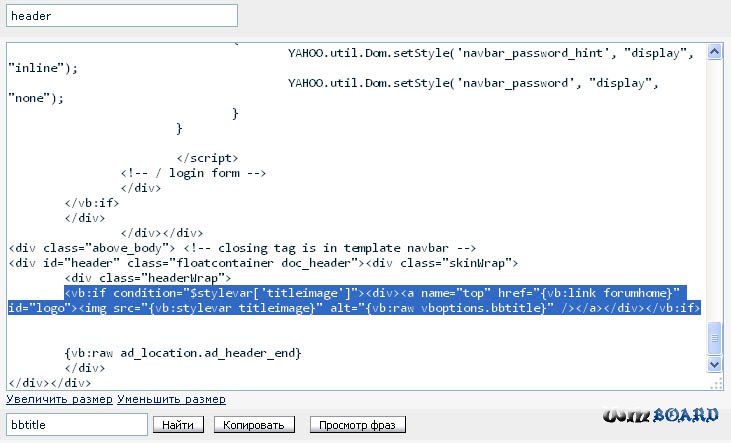
Поэтому сразу же после выполненных выше действий открываете файл /includes/class_image.php, ищете
imagejpeg($image, '', $quality);
Меняете на
imagejpeg($image, NULL, $quality);
Теперь все.
Возвращаемся на первые страницы этой темы, и настраиваем свой форум



 И как тут не вспомнить девиз нашей Льюви. Админы, изучайте админку
И как тут не вспомнить девиз нашей Льюви. Админы, изучайте админку 

 Читателей и так весь Рунет.
Читателей и так весь Рунет.


 Ошибка 404.
Чтобы mod_rewrite заработал необходимо внести правила перенаправлений в .htaccess.
Ошибка 404.
Чтобы mod_rewrite заработал необходимо внести правила перенаправлений в .htaccess.

 ardon:
ardon:
 Если стоят спасибки никто не пользуется почти стандартной репой.
Если стоят спасибки никто не пользуется почти стандартной репой.